 An Interface Specification:
An Interface Specification:
|
| Abstract |
The Message Passing Interface Standard (MPI) is a message passing library
standard based on the consensus of the MPI Forum, which has over 40
participating organizations, including vendors, researchers, software library
developers, and users. The goal of the Message Passing Interface is to
establish a portable, efficient, and flexible standard for message passing
that will be widely used for writing message passing programs. As such, MPI
is the first standardized, vendor independent, message passing library. The
advantages of developing message passing software using MPI closely match the
design goals of portability, efficiency, and flexibility. MPI is not an
IEEE or ISO standard, but has in fact, become the "industry standard" for
writing message passing programs on HPC platforms.
The goal of this tutorial is to teach those unfamiliar with MPI how to develop and run parallel programs according to the MPI standard. The primary topics that are presented focus on those which are the most useful for new MPI programmers. The tutorial begins with an introduction, background, and basic information for getting started with MPI. This is followed by a detailed look at the MPI routines that are most useful for new MPI programmers, including MPI Environment Management, Point-to-Point Communications, and Collective Communications routines. Numerous examples in both C and Fortran are provided, as well as a lab exercise.
The tutorial materials also include more advanced topics such as Derived Data Types, Group and Communicator Management Routines, and Virtual Topologies. However, these are not actually presented during the lecture, but are meant to serve as "further reading" for those who are interested.
Level/Prerequisites: Ideal for those who are new to parallel
programming with MPI. A basic understanding of parallel programming
in C or Fortran is assumed. For those who are unfamiliar with Parallel
Programming in general, the material covered in
EC3500: Introduction To Parallel
Computing would be helpful.
| What is MPI? |
An Interface Specification:
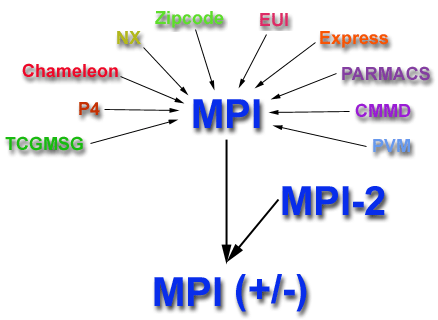
History and Evolution:
|
|
|
Reasons for Using MPI:
Programming Model:
| Getting Started |
Header File:
| C include file | Fortran include file |
|---|---|
| #include "mpi.h" | include 'mpif.h' |
Format of MPI Calls:
| C Binding | |
|---|---|
| Format: | |
| Example: | |
| Error code: | Returned as "rc". MPI_SUCCESS if successful |
| Fortran Binding | |
|---|---|
| Format: | call mpi_xxxxx(parameter,..., ierr) |
| Example: | |
| Error code: | Returned as "ierr" parameter. MPI_SUCCESS if successful |
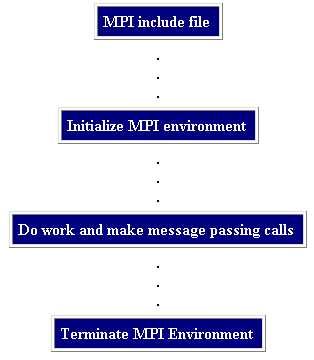
General MPI Program Structure:
|
Communicators and Groups:
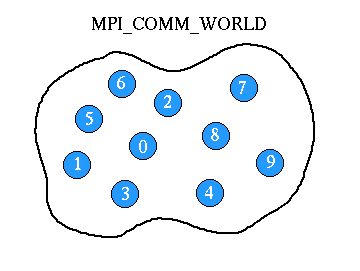 |
Rank:
| Environment Management Routines |
MPI environment management routines are used for an assortment of
purposes, such as initializing and terminating the MPI environment,
querying the environment and identity, etc. Most of the commonly used
ones are described below.
MPI_INIT (ierr)
MPI_COMM_SIZE (comm,size,ierr)
MPI_COMM_RANK (comm,rank,ierr)
MPI_ABORT (comm,errorcode,ierr)
MPI_GET_PROCESSOR_NAME (name,resultlength,ierr)
MPI_INITIALIZED (flag,ierr)
MPI_WTIME ()
MPI_WTICK ()
MPI_FINALIZE (ierr)
#include "mpi.h"
#include <stdio.h>
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, rc;
rc = MPI_Init(&argc,&argv);
if (rc != MPI_SUCCESS) {
printf ("Error starting MPI program. Terminating.\n");
MPI_Abort(MPI_COMM_WORLD, rc);
}
MPI_Comm_size(MPI_COMM_WORLD,&numtasks);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
printf ("Number of tasks= %d My rank= %d\n", numtasks,rank);
/******* do some work *******/
MPI_Finalize();
}
|
program simple
include 'mpif.h'
integer numtasks, rank, ierr, rc
call MPI_INIT(ierr)
if (ierr .ne. MPI_SUCCESS) then
print *,'Error starting MPI program. Terminating.'
call MPI_ABORT(MPI_COMM_WORLD, rc, ierr)
end if
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
print *, 'Number of tasks=',numtasks,' My rank=',rank
C ****** do some work ******
call MPI_FINALIZE(ierr)
end
|
| Point to Point Communication Routines |
Types of Point-to-Point Operations:
Buffering:
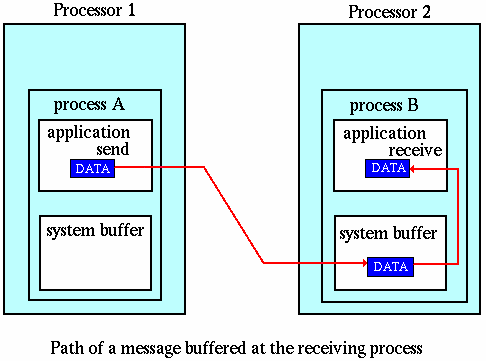
Blocking vs. Non-blocking:
Order and Fairness:
| Point to Point Communication Routines |
| Blocking sends | |
| Non-blocking sends | |
| Blocking receive | |
| Non-blocking receive |
| C Data Types | Fortran Data Types | ||
|---|---|---|---|
| MPI_CHAR | signed char | MPI_CHARACTER | character(1) |
| MPI_SHORT | signed short int | ||
| MPI_INT | signed int | MPI_INTEGER | integer |
| MPI_LONG | signed long int | ||
| MPI_UNSIGNED_CHAR | unsigned char | ||
| MPI_UNSIGNED_SHORT | unsigned short int | ||
| MPI_UNSIGNED | unsigned int | ||
| MPI_UNSIGNED_LONG | unsigned long int | ||
| MPI_FLOAT | float | MPI_REAL | real |
| MPI_DOUBLE | double | MPI_DOUBLE_PRECISION | double precision |
| MPI_LONG_DOUBLE | long double | ||
| MPI_COMPLEX | complex | ||
| MPI_DOUBLE_COMPLEX | double complex | ||
| MPI_LOGICAL | logical | ||
| MPI_BYTE | 8 binary digits | MPI_BYTE | 8 binary digits |
| MPI_PACKED | data packed or unpacked with MPI_Pack()/ MPI_Unpack | MPI_PACKED | data packed or unpacked with MPI_Pack()/ MPI_Unpack |
Notes:
| Point to Point Communication Routines |
MPI_SEND (buf,count,datatype,dest,tag,comm,ierr)
MPI_RECV (buf,count,datatype,source,tag,comm,status,ierr)
MPI_SSEND (buf,count,datatype,dest,tag,comm,ierr)
MPI_BSEND (buf,count,datatype,dest,tag,comm,ierr)
MPI_Buffer_detach (&buffer,size)
MPI_BUFFER_ATTACH (buffer,size,ierr)
MPI_BUFFER_DETACH (buffer,size,ierr)
MPI_RSEND (buf,count,datatype,dest,tag,comm,ierr)
......
&recvbuf,recvcount,recvtype,source,recvtag,
......
comm,&status)
MPI_SENDRECV (sendbuf,sendcount,sendtype,dest,sendtag,
......
recvbuf,recvcount,recvtype,source,recvtag,
......
comm,status,ierr)
MPI_Waitany (count,&array_of_requests,&index,&status)
MPI_Waitall (count,&array_of_requests,&array_of_statuses)
MPI_Waitsome (incount,&array_of_requests,&outcount,
......
&array_of_offsets, &array_of_statuses)
MPI_WAIT (request,status,ierr)
MPI_WAITANY (count,array_of_requests,index,status,ierr)
MPI_WAITALL (count,array_of_requests,array_of_statuses,
......
ierr)
MPI_WAITSOME (incount,array_of_requests,outcount,
......
array_of_offsets, array_of_statuses,ierr)
MPI_PROBE (source,tag,comm,status,ierr)
Task 0 pings task 1 and awaits return ping
#include "mpi.h"
#include <stdio.h>
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, dest, source, rc, count, tag=1;
char inmsg, outmsg='x';
MPI_Status Stat;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if (rank == 0) {
dest = 1;
source = 1;
rc = MPI_Send(&outmsg, 1, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
rc = MPI_Recv(&inmsg, 1, MPI_CHAR, source, tag, MPI_COMM_WORLD, &Stat);
}
else if (rank == 1) {
dest = 0;
source = 0;
rc = MPI_Recv(&inmsg, 1, MPI_CHAR, source, tag, MPI_COMM_WORLD, &Stat);
rc = MPI_Send(&outmsg, 1, MPI_CHAR, dest, tag, MPI_COMM_WORLD);
}
rc = MPI_Get_count(&Stat, MPI_CHAR, &count);
printf("Task %d: Received %d char(s) from task %d with tag %d \n",
rank, count, Stat.MPI_SOURCE, Stat.MPI_TAG);
MPI_Finalize();
}
|
program ping
include 'mpif.h'
integer numtasks, rank, dest, source, count, tag, ierr
integer stat(MPI_STATUS_SIZE)
character inmsg, outmsg
outmsg = 'x'
tag = 1
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
if (rank .eq. 0) then
dest = 1
source = 1
call MPI_SEND(outmsg, 1, MPI_CHARACTER, dest, tag,
& MPI_COMM_WORLD, ierr)
call MPI_RECV(inmsg, 1, MPI_CHARACTER, source, tag,
& MPI_COMM_WORLD, stat, ierr)
else if (rank .eq. 1) then
dest = 0
source = 0
call MPI_RECV(inmsg, 1, MPI_CHARACTER, source, tag,
& MPI_COMM_WORLD, stat, err)
call MPI_SEND(outmsg, 1, MPI_CHARACTER, dest, tag,
& MPI_COMM_WORLD, err)
endif
call MPI_GET_COUNT(stat, MPI_CHARACTER, count, ierr)
print *, 'Task ',rank,': Received', count, 'char(s) from task',
& stat(MPI_SOURCE), 'with tag',stat(MPI_TAG)
call MPI_FINALIZE(ierr)
end
|
| Point to Point Communication Routines |
MPI_ISEND (buf,count,datatype,dest,tag,comm,request,ierr)
MPI_IRECV (buf,count,datatype,source,tag,comm,request,ierr)
MPI_ISSEND (buf,count,datatype,dest,tag,comm,request,ierr)
MPI_IBSEND (buf,count,datatype,dest,tag,comm,request,ierr)
MPI_IRSEND (buf,count,datatype,dest,tag,comm,request,ierr)
MPI_Testany (count,&array_of_requests,&index,&flag,&status)
MPI_Testall (count,&array_of_requests,&flag,&array_of_statuses)
MPI_Testsome (incount,&array_of_requests,&outcount,
......
&array_of_offsets, &array_of_statuses)
MPI_TEST (request,flag,status,ierr)
MPI_TESTANY (count,array_of_requests,index,flag,status,ierr)
MPI_TESTALL (count,array_of_requests,flag,array_of_statuses,ierr)
MPI_TESTSOME (incount,array_of_requests,outcount,
......
array_of_offsets, array_of_statuses,ierr)
MPI_IPROBE (source,tag,comm,flag,status,ierr)
Nearest neighbor exchange in ring topology
#include "mpi.h"
#include <stdio.h>
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, next, prev, buf[2], tag1=1, tag2=2;
MPI_Request reqs[4];
MPI_Status stats[4];
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
prev = rank-1;
next = rank+1;
if (rank == 0) prev = numtasks - 1;
if (rank == (numtasks - 1)) next = 0;
MPI_Irecv(&buf[0], 1, MPI_INT, prev, tag1, MPI_COMM_WORLD, &reqs[0]);
MPI_Irecv(&buf[1], 1, MPI_INT, next, tag2, MPI_COMM_WORLD, &reqs[1]);
MPI_Isend(&rank, 1, MPI_INT, prev, tag2, MPI_COMM_WORLD, &reqs[2]);
MPI_Isend(&rank, 1, MPI_INT, next, tag1, MPI_COMM_WORLD, &reqs[3]);
{ do some work }
MPI_Waitall(4, reqs, stats);
MPI_Finalize();
}
|
program ringtopo
include 'mpif.h'
integer numtasks, rank, next, prev, buf(2), tag1, tag2, ierr
integer stats(MPI_STATUS_SIZE,4), reqs(4)
tag1 = 1
tag2 = 2
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
prev = rank - 1
next = rank + 1
if (rank .eq. 0) then
prev = numtasks - 1
endif
if (rank .eq. numtasks - 1) then
next = 0
endif
call MPI_IRECV(buf(1), 1, MPI_INTEGER, prev, tag1,
& MPI_COMM_WORLD, reqs(1), ierr)
call MPI_IRECV(buf(2), 1, MPI_INTEGER, next, tag2,
& MPI_COMM_WORLD, reqs(2), ierr)
call MPI_ISEND(rank, 1, MPI_INTEGER, prev, tag2,
& MPI_COMM_WORLD, reqs(3), ierr)
call MPI_ISEND(rank, 1, MPI_INTEGER, next, tag1,
& MPI_COMM_WORLD, reqs(4), ierr)
C do some work
call MPI_WAITALL(4, reqs, stats, ierr);
call MPI_FINALIZE(ierr)
end
|
| Collective Communication Routines |
All or None:
Types of Collective Operations:
Programming Considerations and Restrictions:
MPI_BARRIER (comm,ierr)
MPI_BCAST (buffer,count,datatype,root,comm,ierr)
......
recvcnt,recvtype,root,comm)
MPI_SCATTER (sendbuf,sendcnt,sendtype,recvbuf,
......
recvcnt,recvtype,root,comm,ierr)
......
recvcount,recvtype,root,comm)
MPI_GATHER (sendbuf,sendcnt,sendtype,recvbuf,
......
recvcount,recvtype,root,comm,ierr)
......
recvcount,recvtype,comm)
MPI_ALLGATHER (sendbuf,sendcount,sendtype,recvbuf,
......
recvcount,recvtype,comm,info)
MPI_REDUCE (sendbuf,recvbuf,count,datatype,op,root,comm,ierr)
The predefined MPI reduction operations appear below. Users can also define their own reduction functions by using the MPI_Op_create routine.
| MPI Reduction Operation | C Data Types | Fortran Data Type | |
|---|---|---|---|
| MPI_MAX | maximum | integer, float | integer, real, complex |
| MPI_MIN | minimum | integer, float | integer, real, complex |
| MPI_SUM | sum | integer, float | integer, real, complex |
| MPI_PROD | product | integer, float | integer, real, complex |
| MPI_LAND | logical AND | integer | logical |
| MPI_BAND | bit-wise AND | integer, MPI_BYTE | integer, MPI_BYTE |
| MPI_LOR | logical OR | integer | logical |
| MPI_BOR | bit-wise OR | integer, MPI_BYTE | integer, MPI_BYTE |
| MPI_LXOR | logical XOR | integer | logical |
| MPI_BXOR | bit-wise XOR | integer, MPI_BYTE | integer, MPI_BYTE |
| MPI_MAXLOC | max value and location | float, double and long double | real, complex,double precision |
| MPI_MINLOC | min value and location | float, double and long double | real, complex, double precision |
MPI_ALLREDUCE (sendbuf,recvbuf,count,datatype,op,comm,ierr)
......
op,comm)
MPI_REDUCE_SCATTER (sendbuf,recvbuf,recvcount,datatype,
......
op,comm,ierr)
......
recvcnt,recvtype,comm)
MPI_ALLTOALL (sendbuf,sendcount,sendtype,recvbuf,
......
recvcnt,recvtype,comm,ierr)
MPI_SCAN (sendbuf,recvbuf,count,datatype,op,comm,ierr)
Perform a scatter operation on the rows of an array
#include "mpi.h"
#include <stdio.h>
#define SIZE 4
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, sendcount, recvcount, source;
float sendbuf[SIZE][SIZE] = {
{1.0, 2.0, 3.0, 4.0},
{5.0, 6.0, 7.0, 8.0},
{9.0, 10.0, 11.0, 12.0},
{13.0, 14.0, 15.0, 16.0} };
float recvbuf[SIZE];
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
if (numtasks == SIZE) {
source = 1;
sendcount = SIZE;
recvcount = SIZE;
MPI_Scatter(sendbuf,sendcount,MPI_FLOAT,recvbuf,recvcount,
MPI_FLOAT,source,MPI_COMM_WORLD);
printf("rank= %d Results: %f %f %f %f\n",rank,recvbuf[0],
recvbuf[1],recvbuf[2],recvbuf[3]);
}
else
printf("Must specify %d processors. Terminating.\n",SIZE);
MPI_Finalize();
}
|
program scatter
include 'mpif.h'
integer SIZE
parameter(SIZE=4)
integer numtasks, rank, sendcount, recvcount, source, ierr
real*4 sendbuf(SIZE,SIZE), recvbuf(SIZE)
C Fortran stores this array in column major order, so the
C scatter will actually scatter columns, not rows.
data sendbuf /1.0, 2.0, 3.0, 4.0,
& 5.0, 6.0, 7.0, 8.0,
& 9.0, 10.0, 11.0, 12.0,
& 13.0, 14.0, 15.0, 16.0 /
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
if (numtasks .eq. SIZE) then
source = 1
sendcount = SIZE
recvcount = SIZE
call MPI_SCATTER(sendbuf, sendcount, MPI_REAL, recvbuf,
& recvcount, MPI_REAL, source, MPI_COMM_WORLD, ierr)
print *, 'rank= ',rank,' Results: ',recvbuf
else
print *, 'Must specify',SIZE,' processors. Terminating.'
endif
call MPI_FINALIZE(ierr)
end
|
rank= 0 Results: 1.000000 2.000000 3.000000 4.000000 rank= 1 Results: 5.000000 6.000000 7.000000 8.000000 rank= 2 Results: 9.000000 10.000000 11.000000 12.000000 rank= 3 Results: 13.000000 14.000000 15.000000 16.000000
| Derived Data Types |
| C Data Types | Fortran Data Types |
|---|---|
| MPI_CHAR
MPI_SHORT MPI_INT MPI_LONG MPI_UNSIGNED_CHAR MPI_UNSIGNED_SHORT MPI_UNSIGNED_LONG MPI_UNSIGNED MPI_FLOAT MPI_DOUBLE MPI_LONG_DOUBLE MPI_BYTE MPI_PACKED | MPI_CHARACTER
MPI_INTEGER MPI_REAL MPI_DOUBLE_PRECISION MPI_COMPLEX MPI_DOUBLE_COMPLEX MPI_LOGICAL MPI_BYTE MPI_PACKED |
MPI_TYPE_CONTIGUOUS (count,oldtype,newtype,ierr)
MPI_TYPE_VECTOR (count,blocklength,stride,oldtype,newtype,ierr)
MPI_TYPE_INDEXED (count,blocklens(),offsets(),old_type,newtype,ierr)
MPI_TYPE_STRUCT (count,blocklens(),offsets(),old_types,newtype,ierr)
MPI_TYPE_EXTENT (datatype,extent,ierr)
MPI_TYPE_COMMIT (datatype,ierr)
MPI_TYPE_FREE (datatype,ierr)
Create a data type representing a row of an array and distribute a
different row to all processes.
#include "mpi.h"
#include <stdio.h>
#define SIZE 4
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, source=0, dest, tag=1, i;
float a[SIZE][SIZE] =
{1.0, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0,
9.0, 10.0, 11.0, 12.0,
13.0, 14.0, 15.0, 16.0};
float b[SIZE];
MPI_Status stat;
MPI_Datatype rowtype;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Type_contiguous(SIZE, MPI_FLOAT, &rowtype);
MPI_Type_commit(&rowtype);
if (numtasks == SIZE) {
if (rank == 0) {
for (i=0; i<numtasks; i++)
MPI_Send(&a[i][0], 1, rowtype, i, tag, MPI_COMM_WORLD);
}
MPI_Recv(b, SIZE, MPI_FLOAT, source, tag, MPI_COMM_WORLD, &stat);
printf("rank= %d b= %3.1f %3.1f %3.1f %3.1f\n",
rank,b[0],b[1],b[2],b[3]);
}
else
printf("Must specify %d processors. Terminating.\n",SIZE);
MPI_Type_free(&rowtype);
MPI_Finalize();
}
|
program contiguous
include 'mpif.h'
integer SIZE
parameter(SIZE=4)
integer numtasks, rank, source, dest, tag, i, ierr
real*4 a(0:SIZE-1,0:SIZE-1), b(0:SIZE-1)
integer stat(MPI_STATUS_SIZE), columntype
C Fortran stores this array in column major order
data a /1.0, 2.0, 3.0, 4.0,
& 5.0, 6.0, 7.0, 8.0,
& 9.0, 10.0, 11.0, 12.0,
& 13.0, 14.0, 15.0, 16.0 /
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
call MPI_TYPE_CONTIGUOUS(SIZE, MPI_REAL, columntype, ierr)
call MPI_TYPE_COMMIT(columntype, ierr)
tag = 1
if (numtasks .eq. SIZE) then
if (rank .eq. 0) then
do 10 i=0, numtasks-1
call MPI_SEND(a(0,i), 1, columntype, i, tag,
& MPI_COMM_WORLD,ierr)
10 continue
endif
source = 0
call MPI_RECV(b, SIZE, MPI_REAL, source, tag,
& MPI_COMM_WORLD, stat, ierr)
print *, 'rank= ',rank,' b= ',b
else
print *, 'Must specify',SIZE,' processors. Terminating.'
endif
call MPI_TYPE_FREE(columntype, ierr)
call MPI_FINALIZE(ierr)
end
|
rank= 0 b= 1.0 2.0 3.0 4.0 rank= 1 b= 5.0 6.0 7.0 8.0 rank= 2 b= 9.0 10.0 11.0 12.0 rank= 3 b= 13.0 14.0 15.0 16.0
Create a data type representing a column of an array and distribute
different columns to all processes.
#include "mpi.h"
#include <stdio.h>
#define SIZE 4
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, source=0, dest, tag=1, i;
float a[SIZE][SIZE] =
{1.0, 2.0, 3.0, 4.0,
5.0, 6.0, 7.0, 8.0,
9.0, 10.0, 11.0, 12.0,
13.0, 14.0, 15.0, 16.0};
float b[SIZE];
MPI_Status stat;
MPI_Datatype columntype;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
MPI_Type_vector(SIZE, 1, SIZE, MPI_FLOAT, &columntype);
MPI_Type_commit(&columntype);
if (numtasks == SIZE) {
if (rank == 0) {
for (i=0; i<numtasks; i++)
MPI_Send(&a[0][i], 1, columntype, i, tag, MPI_COMM_WORLD);
}
MPI_Recv(b, SIZE, MPI_FLOAT, source, tag, MPI_COMM_WORLD, &stat);
printf("rank= %d b= %3.1f %3.1f %3.1f %3.1f\n",
rank,b[0],b[1],b[2],b[3]);
}
else
printf("Must specify %d processors. Terminating.\n",SIZE);
MPI_Type_free(&columntype);
MPI_Finalize();
}
|
program vector
include 'mpif.h'
integer SIZE
parameter(SIZE=4)
integer numtasks, rank, source, dest, tag, i, ierr
real*4 a(0:SIZE-1,0:SIZE-1), b(0:SIZE-1)
integer stat(MPI_STATUS_SIZE), rowtype
C Fortran stores this array in column major order
data a /1.0, 2.0, 3.0, 4.0,
& 5.0, 6.0, 7.0, 8.0,
& 9.0, 10.0, 11.0, 12.0,
& 13.0, 14.0, 15.0, 16.0 /
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
call MPI_TYPE_VECTOR(SIZE, 1, SIZE, MPI_REAL, rowtype, ierr)
call MPI_TYPE_COMMIT(rowtype, ierr)
tag = 1
if (numtasks .eq. SIZE) then
if (rank .eq. 0) then
do 10 i=0, numtasks-1
call MPI_SEND(a(i,0), 1, rowtype, i, tag,
& MPI_COMM_WORLD, ierr)
10 continue
endif
source = 0
call MPI_RECV(b, SIZE, MPI_REAL, source, tag,
& MPI_COMM_WORLD, stat, ierr)
print *, 'rank= ',rank,' b= ',b
else
print *, 'Must specify',SIZE,' processors. Terminating.'
endif
call MPI_TYPE_FREE(rowtype, ierr)
call MPI_FINALIZE(ierr)
end
|
rank= 0 b= 1.0 5.0 9.0 13.0 rank= 1 b= 2.0 6.0 10.0 14.0 rank= 2 b= 3.0 7.0 11.0 15.0 rank= 3 b= 4.0 8.0 12.0 16.0
Create a datatype by extracting variable portions of an array and distribute
to all tasks.
#include "mpi.h"
#include <stdio.h>
#define NELEMENTS 6
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, source=0, dest, tag=1, i;
int blocklengths[2], displacements[2];
float a[16] =
{1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0,
9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0};
float b[NELEMENTS];
MPI_Status stat;
MPI_Datatype indextype;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
blocklengths[0] = 4;
blocklengths[1] = 2;
displacements[0] = 5;
displacements[1] = 12;
MPI_Type_indexed(2, blocklengths, displacements, MPI_FLOAT, &indextype);
MPI_Type_commit(&indextype);
if (rank == 0) {
for (i=0; i<numtasks; i++)
MPI_Send(a, 1, indextype, i, tag, MPI_COMM_WORLD);
}
MPI_Recv(b, NELEMENTS, MPI_FLOAT, source, tag, MPI_COMM_WORLD, &stat);
printf("rank= %d b= %3.1f %3.1f %3.1f %3.1f %3.1f %3.1f\n",
rank,b[0],b[1],b[2],b[3],b[4],b[5]);
MPI_Type_free(&indextype);
MPI_Finalize();
}
|
program indexed
include 'mpif.h'
integer NELEMENTS
parameter(NELEMENTS=6)
integer numtasks, rank, source, dest, tag, i, ierr
integer blocklengths(0:1), displacements(0:1)
real*4 a(0:15), b(0:NELEMENTS-1)
integer stat(MPI_STATUS_SIZE), indextype
data a /1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0,
& 9.0, 10.0, 11.0, 12.0, 13.0, 14.0, 15.0, 16.0 /
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
blocklengths(0) = 4
blocklengths(1) = 2
displacements(0) = 5
displacements(1) = 12
call MPI_TYPE_INDEXED(2, blocklengths, displacements, MPI_REAL,
& indextype, ierr)
call MPI_TYPE_COMMIT(indextype, ierr)
tag = 1
if (rank .eq. 0) then
do 10 i=0, numtasks-1
call MPI_SEND(a, 1, indextype, i, tag, MPI_COMM_WORLD, ierr)
10 continue
endif
source = 0
call MPI_RECV(b, NELEMENTS, MPI_REAL, source, tag, MPI_COMM_WORLD,
& stat, ierr)
print *, 'rank= ',rank,' b= ',b
call MPI_TYPE_FREE(indextype, ierr)
call MPI_FINALIZE(ierr)
end
|
rank= 0 b= 6.0 7.0 8.0 9.0 13.0 14.0 rank= 1 b= 6.0 7.0 8.0 9.0 13.0 14.0 rank= 2 b= 6.0 7.0 8.0 9.0 13.0 14.0 rank= 3 b= 6.0 7.0 8.0 9.0 13.0 14.0
Create a data type that represents a particle and distribute an array
of such particles to all processes.
#include "mpi.h"
#include <stdio.h>
#define NELEM 25
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, source=0, dest, tag=1, i;
typedef struct {
float x, y, z;
float velocity;
int n, type;
} Particle;
Particle p[NELEM], particles[NELEM];
MPI_Datatype particletype, oldtypes[2];
int blockcounts[2];
/* MPI_Aint type used to be consistent with syntax of */
/* MPI_Type_extent routine */
MPI_Aint offsets[2], extent;
MPI_Status stat;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
/* Setup description of the 4 MPI_FLOAT fields x, y, z, velocity */
offsets[0] = 0;
oldtypes[0] = MPI_FLOAT;
blockcounts[0] = 4;
/* Setup description of the 2 MPI_INT fields n, type */
/* Need to first figure offset by getting size of MPI_FLOAT */
MPI_Type_extent(MPI_FLOAT, &extent);
offsets[1] = 4 * extent;
oldtypes[1] = MPI_INT;
blockcounts[1] = 2;
/* Now define structured type and commit it */
MPI_Type_struct(2, blockcounts, offsets, oldtypes, &particletype);
MPI_Type_commit(&particletype);
/* Initialize the particle array and then send it to each task */
if (rank == 0) {
for (i=0; i<NELEM; i++) {
particles[i].x = i * 1.0;
particles[i].y = i * -1.0;
particles[i].z = i * 1.0;
particles[i].velocity = 0.25;
particles[i].n = i;
particles[i].type = i % 2;
}
for (i=0; i<numtasks; i++)
MPI_Send(particles, NELEM, particletype, i, tag, MPI_COMM_WORLD);
}
MPI_Recv(p, NELEM, particletype, source, tag, MPI_COMM_WORLD, &stat);
/* Print a sample of what was received */
printf("rank= %d %3.2f %3.2f %3.2f %3.2f %d %d\n", rank,p[3].x,
p[3].y,p[3].z,p[3].velocity,p[3].n,p[3].type);
MPI_Type_free(&particletype);
MPI_Finalize();
}
|
program struct
include 'mpif.h'
integer NELEM
parameter(NELEM=25)
integer numtasks, rank, source, dest, tag, i, ierr
integer stat(MPI_STATUS_SIZE)
type Particle
sequence
real*4 x, y, z, velocity
integer n, type
end type Particle
type (Particle) p(NELEM), particles(NELEM)
integer particletype, oldtypes(0:1), blockcounts(0:1),
& offsets(0:1), extent
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
C Setup description of the 4 MPI_REAL fields x, y, z, velocity
offsets(0) = 0
oldtypes(0) = MPI_REAL
blockcounts(0) = 4
C Setup description of the 2 MPI_INTEGER fields n, type
C Need to first figure offset by getting size of MPI_REAL
call MPI_TYPE_EXTENT(MPI_REAL, extent, ierr)
offsets(1) = 4 * extent
oldtypes(1) = MPI_INTEGER
blockcounts(1) = 2
C Now define structured type and commit it
call MPI_TYPE_STRUCT(2, blockcounts, offsets, oldtypes,
& particletype, ierr)
call MPI_TYPE_COMMIT(particletype, ierr)
C Initialize the particle array and then send it to each task
tag = 1
if (rank .eq. 0) then
do 10 i=0, NELEM-1
particles(i) = Particle ( 1.0*i, -1.0*i, 1.0*i,
& 0.25, i, mod(i,2) )
10 continue
do 20 i=0, numtasks-1
call MPI_SEND(particles, NELEM, particletype, i, tag,
& MPI_COMM_WORLD, ierr)
20 continue
endif
source = 0
call MPI_RECV(p, NELEM, particletype, source, tag,
& MPI_COMM_WORLD, stat, ierr)
print *, 'rank= ',rank,' p(3)= ',p(3)
call MPI_TYPE_FREE(particletype, ierr)
call MPI_FINALIZE(ierr)
end
|
rank= 0 3.00 -3.00 3.00 0.25 3 1 rank= 2 3.00 -3.00 3.00 0.25 3 1 rank= 1 3.00 -3.00 3.00 0.25 3 1 rank= 3 3.00 -3.00 3.00 0.25 3 1
| Group and Communicator Management Routines |
Groups vs. Communicators:
Primary Purposes of Group and Communicator Objects:
Programming Considerations and Restrictions:
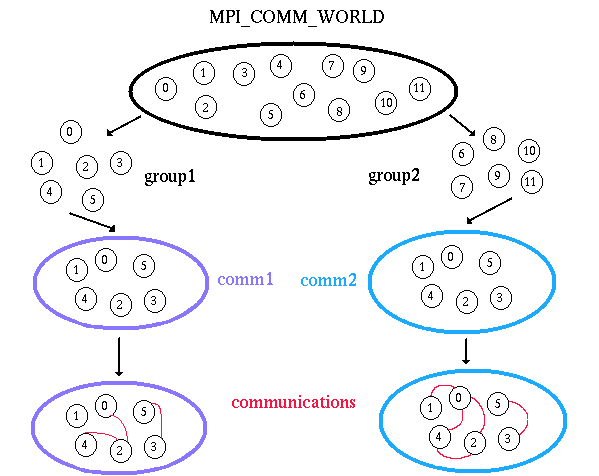
Create two different process groups for separate collective communications exchange. Requires creating new communicators also.
#include "mpi.h"
#include <stdio.h>
#define NPROCS 8
int main(argc,argv)
int argc;
char *argv[]; {
int rank, new_rank, sendbuf, recvbuf, numtasks,
ranks1[4]={0,1,2,3}, ranks2[4]={4,5,6,7};
MPI_Group orig_group, new_group;
MPI_Comm new_comm;
MPI_Init(&argc,&argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
if (numtasks != NPROCS) {
printf("Must specify MP_PROCS= %d. Terminating.\n",NPROCS);
MPI_Finalize();
exit(0);
}
sendbuf = rank;
/* Extract the original group handle */
MPI_Comm_group(MPI_COMM_WORLD, &orig_group);
/* Divide tasks into two distinct groups based upon rank */
if (rank < NPROCS/2) {
MPI_Group_incl(orig_group, NPROCS/2, ranks1, &new_group);
}
else {
MPI_Group_incl(orig_group, NPROCS/2, ranks2, &new_group);
}
/* Create new new communicator and then perform collective communications */
MPI_Comm_create(MPI_COMM_WORLD, new_group, &new_comm);
MPI_Allreduce(&sendbuf, &recvbuf, 1, MPI_INT, MPI_SUM, new_comm);
MPI_Group_rank (new_group, &new_rank);
printf("rank= %d newrank= %d recvbuf= %d\n",rank,new_rank,recvbuf);
MPI_Finalize();
}
|
program group
include 'mpif.h'
integer NPROCS
parameter(NPROCS=8)
integer rank, new_rank, sendbuf, recvbuf, numtasks
integer ranks1(4), ranks2(4), ierr
integer orig_group, new_group, new_comm
data ranks1 /0, 1, 2, 3/, ranks2 /4, 5, 6, 7/
call MPI_INIT(ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
if (numtasks .ne. NPROCS) then
print *, 'Must specify MPROCS= ',NPROCS,' Terminating.'
call MPI_FINALIZE(ierr)
stop
endif
sendbuf = rank
C Extract the original group handle
call MPI_COMM_GROUP(MPI_COMM_WORLD, orig_group, ierr)
C Divide tasks into two distinct groups based upon rank
if (rank .lt. NPROCS/2) then
call MPI_GROUP_INCL(orig_group, NPROCS/2, ranks1,
& new_group, ierr)
else
call MPI_GROUP_INCL(orig_group, NPROCS/2, ranks2,
& new_group, ierr)
endif
call MPI_COMM_CREATE(MPI_COMM_WORLD, new_group,
& new_comm, ierr)
call MPI_ALLREDUCE(sendbuf, recvbuf, 1, MPI_INTEGER,
& MPI_SUM, new_comm, ierr)
call MPI_GROUP_RANK(new_group, new_rank, ierr)
print *, 'rank= ',rank,' newrank= ',new_rank,' recvbuf= ',
& recvbuf
call MPI_FINALIZE(ierr)
end
|
rank= 7 newrank= 3 recvbuf= 22 rank= 0 newrank= 0 recvbuf= 6 rank= 1 newrank= 1 recvbuf= 6 rank= 2 newrank= 2 recvbuf= 6 rank= 6 newrank= 2 recvbuf= 22 rank= 3 newrank= 3 recvbuf= 6 rank= 4 newrank= 0 recvbuf= 22 rank= 5 newrank= 1 recvbuf= 22
| Virtual Topologies |
What Are They?
Why Use Them?
Example:
A simplified mapping of processes into a Cartesian virtual topology appears below:
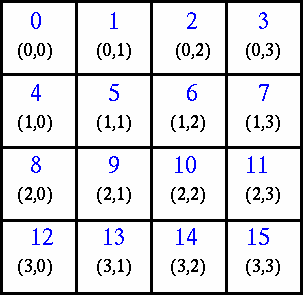
Create a 4 x 4 Cartesian topology from 16 processors and have each process exchange its rank with four neighbors.
#include "mpi.h"
#include <stdio.h>
#define SIZE 16
#define UP 0
#define DOWN 1
#define LEFT 2
#define RIGHT 3
int main(argc,argv)
int argc;
char *argv[]; {
int numtasks, rank, source, dest, outbuf, i, tag=1,
inbuf[4]={MPI_PROC_NULL,MPI_PROC_NULL,MPI_PROC_NULL,MPI_PROC_NULL,},
nbrs[4], dims[2]={4,4},
periods[2]={0,0}, reorder=0, coords[2];
MPI_Request reqs[8];
MPI_Status stats[8];
MPI_Comm cartcomm;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD, &numtasks);
if (numtasks == SIZE) {
MPI_Cart_create(MPI_COMM_WORLD, 2, dims, periods, reorder, &cartcomm);
MPI_Comm_rank(cartcomm, &rank);
MPI_Cart_coords(cartcomm, rank, 2, coords);
MPI_Cart_shift(cartcomm, 0, 1, &nbrs[UP], &nbrs[DOWN]);
MPI_Cart_shift(cartcomm, 1, 1, &nbrs[LEFT], &nbrs[RIGHT]);
outbuf = rank;
for (i=0; i<4; i++) {
dest = nbrs[i];
source = nbrs[i];
MPI_Isend(&outbuf, 1, MPI_INT, dest, tag,
MPI_COMM_WORLD, &reqs[i]);
MPI_Irecv(&inbuf[i], 1, MPI_INT, source, tag,
MPI_COMM_WORLD, &reqs[i+4]);
}
MPI_Waitall(8, reqs, stats);
printf("rank= %d coords= %d %d neighbors(u,d,l,r)= %d %d %d %d\n",
rank,coords[0],coords[1],nbrs[UP],nbrs[DOWN],nbrs[LEFT],
nbrs[RIGHT]);
printf("rank= %d inbuf(u,d,l,r)= %d %d %d %d\n",
rank,inbuf[UP],inbuf[DOWN],inbuf[LEFT],inbuf[RIGHT]);
}
else
printf("Must specify %d processors. Terminating.\n",SIZE);
MPI_Finalize();
}
|
program cartesian
include 'mpif.h'
integer SIZE, UP, DOWN, LEFT, RIGHT
parameter(SIZE=16)
parameter(UP=1)
parameter(DOWN=2)
parameter(LEFT=3)
parameter(RIGHT=4)
integer numtasks, rank, source, dest, outbuf, i, tag, ierr,
& inbuf(4), nbrs(4), dims(2), coords(2),
& stats(MPI_STATUS_SIZE, 8), reqs(8), cartcomm,
& periods(2), reorder
data inbuf /MPI_PROC_NULL,MPI_PROC_NULL,MPI_PROC_NULL,
& MPI_PROC_NULL/, dims /4,4/, tag /1/,
& periods /0,0/, reorder /0/
call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, numtasks, ierr)
if (numtasks .eq. SIZE) then
call MPI_CART_CREATE(MPI_COMM_WORLD, 2, dims, periods, reorder,
& cartcomm, ierr)
call MPI_COMM_RANK(cartcomm, rank, ierr)
call MPI_CART_COORDS(cartcomm, rank, 2, coords, ierr)
print *,'rank= ',rank,'coords= ',coords
call MPI_CART_SHIFT(cartcomm, 0, 1, nbrs(UP), nbrs(DOWN), ierr)
call MPI_CART_SHIFT(cartcomm, 1, 1, nbrs(LEFT), nbrs(RIGHT),
& ierr)
outbuf = rank
do i=1,4
dest = nbrs(i)
source = nbrs(i)
call MPI_ISEND(outbuf, 1, MPI_INTEGER, dest, tag,
& MPI_COMM_WORLD, reqs(i), ierr)
call MPI_IRECV(inbuf(i), 1, MPI_INTEGER, source, tag,
& MPI_COMM_WORLD, reqs(i+4), ierr)
enddo
call MPI_WAITALL(8, reqs, stats, ierr)
print *,'rank= ',rank,' coords= ',coords,
& ' neighbors(u,d,l,r)= ',nbrs
print *,'rank= ',rank,' ',
& ' inbuf(u,d,l,r)= ',inbuf
else
print *, 'Must specify',SIZE,' processors. Terminating.'
endif
call MPI_FINALIZE(ierr)
end
|
rank= 0 coords= 0 0 neighbors(u,d,l,r)= -3 4 -3 1
rank= 0 inbuf(u,d,l,r)= -3 4 -3 1
rank= 1 coords= 0 1 neighbors(u,d,l,r)= -3 5 0 2
rank= 1 inbuf(u,d,l,r)= -3 5 0 2
rank= 2 coords= 0 2 neighbors(u,d,l,r)= -3 6 1 3
rank= 2 inbuf(u,d,l,r)= -3 6 1 3
. . . . .
rank= 14 coords= 3 2 neighbors(u,d,l,r)= 10 -3 13 15
rank= 14 inbuf(u,d,l,r)= 10 -3 13 15
rank= 15 coords= 3 3 neighbors(u,d,l,r)= 11 -3 14 -3
rank= 15 inbuf(u,d,l,r)= 11 -3 14 -3
| A Brief Word on MPI-2 |
History:
Key Areas of New Functionality:
More Information on MPI-2:
| LLNL Specific Information and Recommendations |
MPI Implementations:
| Platform | Implementations | Comments |
|---|---|---|
| IBM AIX | IBM MPI threaded library | Recommended |
| IBM MPI signal library | Not thread safe and not recommended. POWER3 systems only. | |
| MPICH | Not thread safe. POWER3 systems only. | |
| Intel Linux | Quadrics MPI | Recommended. Uses shared memory for on-node communications and message passing over the Quadrics switch for inter-node communications. Not thread-safe |
| MPICH shared memory | On-node communications. Not thread safe. Only for machines without a Quadrics switch. | |
| COMPAQ Tru64 | Compaq MPI shared memory | On-node communications. Use -pthread compile flag for thread-safety. |
| MPICH shared memory | On-node communications. Not thread safe | |
| MPICH P4 | Inter-node communications. Not thread safe. Not recommeded due to lack of high speed interconnect between nodes (no switch). |
Compiling, Linking, Running:
| Platform | Implementations | Compile/Link Run |
|---|---|---|
| IBM AIX | IBM MPI threaded library |
mpcc_r code.c mpxlc_r code.c mpguidec code.c mpCC_r code.C mpxlC_r code.C mpguidec++ code.c mpxlf_r code.f mpguidef77 code.f mpxlf90_r code.F mpguidef90 code.F mpxlf95_r code.fSet required POE environment variables, then either: a.out args poe a.out args Or, use POE flags instead of environment variables:
|
| IBM MPI signal library (POWER3 systems only) |
setenv LLNL_COMPILE_SINGLE_THREADED TRUE mpcc code.c mpxlc code.c mpCC code.C mpxlC code.C mpxlf code.f mpxlf90 code.F mpxlf95 code.fSet required POE environment variables, then either: a.out args poe a.out args
Or, use POE flags instead of environment variables:
|
|
| MPICH (POWER3 systems only) |
setenv LLNL_COMPILE_SINGLE_THREADED TRUE mpicc code.c mpiCC code.C mpif77 code.f mpif90 code.F mpirun -nodes n -np p a.out args - OR - setenv MP_NODES n mpirun -np p a.out args |
|
| Intel Linux | Quadrics MPI
(clusters with a Quadrics switch only) |
mpicc code.c mpiicc code.c mpipgcc code.c mpiCC code.C mpipgCC code.C mpif77 code.f mpiifc code.f mpipgf77 code.f mpif90 code.F mpipgf90 code.F srun -n n -p partition a.out args |
| MPICH shared memory
(clusters without a Quadrics switch) |
mpicc code.c mpiicc code.c mpipgcc code.c mpiCC code.C mpipgCC code.C mpif77 code.f mpiifc code.f mpipgf77 code.f mpif90 code.F mpipgf90 code.F mpirun -nodes n -np p a.out args |
|
| COMPAQ Tru64 | Compaq MPI shared memory |
cc code.c -lmpi -pthread gcc code.c -lmpi -pthread cxx code.C -lmpi -pthread KCC code.C -lmpi -pthread g++ code.C -lmpi -pthread f77 code.f -lfmpi -lmpi -pthread f90 code.F -lfmpi -lmpi -pthread dmpirun -np p a.out args |
| MPICH shared memory |
mpicc code.c mpiCC code.C mpicxx code.C mpif77 code.f mpif90 code.F mpirun -np p a.out args |
|
| MPICH P4 |
mpicc_p4 code.c mpiCC_p4 code.C mpicxx_p4 code.C mpif77_p4 code.f mpif90_p4 code.F mpirun_p4 -machinefile user_machine_file -np p a.out args |
Environment Variables:
32-bit versus 64-bit:
More information:
This completes the tutorial.
 |
Please complete the online evaluation form - unless you are doing the exercise, in which case please complete it at the end of the exercise. |
Where would you like to go now?
| References and More Information |
| Appendix A: MPI-1 Routine Index |